
Logstash 是 JRuby 编写的基于消息的开源日志收集和管理系统。 Logstash 解决问题的是收集日志到中心存储,并能进行方便的搜索和查询。 关于 log 的介绍和搭建在网上有很多使用教程,这里主要就我们使用 Logstash 的解决的问题和一些心得进行总结。
解决的问题
我们将 online service 的日志都发送到 Logstash, 其中包含的主要信息有 request 的 context 和 exception 等信息。 下面就是我们其中一条日志信息(删除了部分敏感信息):
{
"_index":"reco-reco_online_request-2015.02.03",
"_type":"reco_online_request",
"_id":"oRYgx6ByS1WHqMMCCipEqw", "_score":1,
"_source":{
"@version":"1",
"@timestamp":"2015-02-03T07:43:23.612Z",
"host":"iad-reco-service-prod-15",
"type":"reco_online_request",
"query":"$XXX",
"treatment":"control",
"system_name":"control:SmartStartSystem",
"status_code":200,
"response_time":13,
"has_behavior_source_exception":false,
"return_count":0,
"result":"{\"result_data\":[]}",
"TimeUsed.FetchUserBehavior":7,
"BehaviorFetch.Atom.Binary.ResponseTime":7,
"TimeUsed.Filter":0,
"TimeUsed.SystemRecommend":8,
"BehaviorFetch.Binary.ResponseTime":7,
"TimeUsed.WriteResult":0,
"TimeUsed.ExtractFeature":0,
"TimeUsed.ParseParameter":5,
"TimeUsed.PostProcess":0,
"TimeUsed.BuildInput":0,
"ResponseTime":13,
"TimeUsed.Retrieve":0,
"Count.Engine.control:SmartStartSystem
SmartStartEngine":0,
"TotalCount.BeforePostProcessor":0,
"TotalCount.AfterPostProcessor":0,
"timestamp":"2015-02-03T07:43:19.082Z"
}
}
每一条 log 包含 request 的各方面信息,这样在某些 request 出现问题的时候,我们就能很方面定位到相应的日志,并能够从日志看到当时的各种 context, 依靠这些 context 信息,我们就能够快读的定位问题或者重现当时的情景。除此之外,我们还会将 log 信息存储 (如 HDFS),以便后续的分析和处理。
下面来看一下我们部署 logstash 的大概架构图:
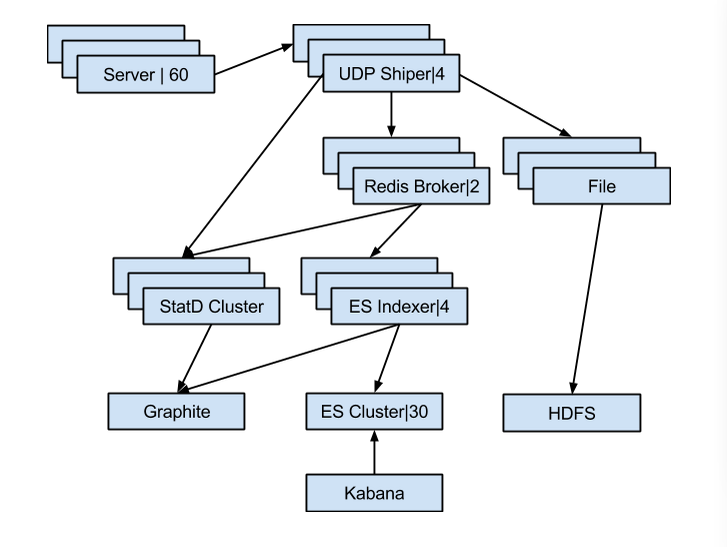
我们的日志都是以 UDP 包的形势发送到 shipper 的, 之后这些日志会发送到 broker (这里就是 redis 队列)和 dump 到文件,因为我们的日志中包含每次 request 的结果信息, 我们需要这些信息对我们的推荐的结果进行分析,之后会有 cron 脚本将这些问题发送到 HDFS 以便后续的分析工作。 除此之外我们还有将一些统计信息发送到 statd, 在 graphite 展示,以便监控当前系统的 exception 信息等。 同时可以监控 logstash 的状态,例如发生严重丢包或者消息阻塞从这些统计信息上就能及时的发现。
Indexer 会从 broker 获取消息, 并将消息索引到 elsticsearch 集群,方便后续的使用查询使用。采用 kabana 作为 elsticsearch 的信息展示和查询界面。同时 indexer 也会有相关的统计发送到 statd, 这样如果消息发生阻塞或者某些组件出现问题就能及时发现。
心得
- Logstash 利用了大量现有的开源软件,并进行整合搭建出一套灵活的解决方案。采用组件的形式组合这个系统,使得系统耦合松散,能够灵活地进行替换。在我们自己的项目开发中很值得借鉴。
- Logstash 采用数据流的形式,数据流的获取和发送渠道多种多样,为数据的处理提供了极大的灵活性, 可能方便的定制各种功能。
- 在记录的日志的过程中,好的日志能够极大的方面我们定位问题,所以我们需要记录“好”的日志。 如果能将各个服务的 log 整合到同一个 Logstash 集群,我们就能够方便的找到一个前端调用的后端调用链,在出现问题的时候快速的定位到出现问题的环节。