
1. 索引
1.1 索引数据结构: B 树, B+ 树
数据库索引的目的是为了提高查询的效率, 就好比字段的索引目录一样。 Mysql 中数据库索引主要是采用 B+ 树的实现的,为什么是 B+ 树呢? 首先了解一下 B 树,B 树相对于查找二叉树有更多的分支,这样可以降低树的高度, 因为每一层的节点可能就意味着一次昂贵的磁盘操作,所以 B 树相对于查找二叉树更加适合做索引。 相对于 B树将索引的键值和指针直接放在响应的节点,B+ 数值将结果存放在叶子节点,这样减少了非叶子节点需要存储的数据,非叶子节点就可以存储更多的索引数据,带来的不好的地方是每一次查询都必须到叶子节点才能找到相应的数据, 但是由于 B+ 树层数较少且一般查询效率取决于读取磁盘的次数,所以这个确定基本是可以忽略的。
1.2 索引类型: 聚簇索引, 非聚簇索引
抽象的区别和定义:聚簇索引的顺序就是数据的物理存储顺序,非聚簇索引顺序与数据物理排列顺序无关。 简单来说就是聚簇索引的索引节点存储的是数据, 非聚簇索引的节点储存的还是一个索引。Innodb 支持聚簇索引和非聚簇索引, MyISAM 只支持非聚簇索引。
1.2.1 聚簇索引
因为聚簇索引的顺序就是数据的物理存储顺序, 所以每一个表只能有一个聚簇索引。
a. 聚簇索引的选取策略
- 如果定义了主键, Innodb 为主键建立聚簇索引
- 如果没有定义主键, 选取第一个 UNIQUE 索引且 NOT NULL 的列建立聚簇索引。
- 如果没有主键且没有 UNIQUE 索引, 创建一个隐藏列作为聚簇索引。
b. 聚簇索引加快查询
根据聚簇索引查询比较快,因为索引和数据存储在一起 (on the same page),相对于非聚簇索引可以减少 IO 读取的次数。
c. 聚簇索引的开销
因为聚簇索引的顺序就是物理存储的顺序,所以在插入或者更新数据的时候,聚簇索引为存在数据重排序的问题。如果在某一页中间插入数据,这样在该页中排在后面的数据就需要移动和重新排序,如果超出了该页的容量也可以还需要涉及到其他页的移动问题(聚簇索引一般都不会写满真个 page, 而是会留有一部分空间,以便后续的插入数据使用)。所以聚簇索引会使得插入/更新速度下降。
d. 聚簇索引的选取
根据聚簇索引的特点, 局促索引的选取应该巨量满足以下原则:
- 避免随机,满足递增/减最好。递增的数据一般会直接追加到聚簇索引中,可以很好的避免重排序和页分裂的问题。AUTO_INCR 很适合做为聚簇索引。
- 不变。 修改聚簇索引会带来重排序的问题。
1.2.2 非聚簇索引
非聚簇索引相对应于聚簇索引,在节点中存数的并不是最终的数据,而是指向最终数据的另一种索引, 所以在查询的过程中会造成更多 IO 开销。
1.2.3 Innodb vs MyISAM
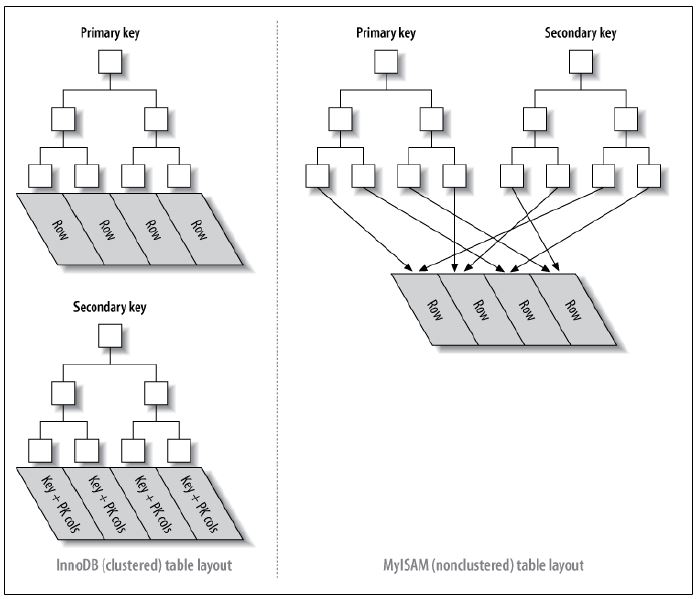
Innodb 的二级索引也是一种类型的非聚簇索引,但是其和 MyISAM 中二级索引的不一样的地方在于其存储的不是数据的直接地址,存储的是主键的值,通过主键的值在找到响应的数据。这样带来的好处是在数据出现页分裂和数据移动的时候(因为采用局促索引组织数据,这样的事情会更经常发生),可以避免需要更新相应的二级索引带来的开销。同样坏处是还需要通过主键查询到响应的数据所在的位置。
参考
[1] https://dev.mysql.com/doc/refman/5.0/en/innodb-index-types.html
[2] https://dev.mysql.com/doc/refman/5.1/en/innodb-table-and-index.html